Market Sentiment Analysis:Machine Learning & NLP
This project investigates the potential relationship between news headlines and stock market trends, aiming to determine whether the sentiment and content within headlines can predict market movements.
I use natural language processing (NLP) techniques to process unstructured text data. All news headlines are converted to lowercase, and stopwords, punctuation, and special characters are removed to standardize the text. Tokenization is then performed to split the headlines into individual tokens. Lemmatization is applied using NLTK's WordNetLemmatizer, which reduces words to their base forms while leaving unchanged those not found in the WordNet corpus.
Feature extraction and engineering techniques were applied to prepare the text data for analysis. TF-IDF (Term Frequency-Inverse Document Frequency) was used to transform textual data into numerical features by emphasizing term importance. Sentiment scores—positive, negative, neutral, and compound—were generated using the VADER model to capture the emotional tone of the text. Named Entity Recognition (NER) was employed to extract meaningful entities, such as organizations, adding further context to the data.

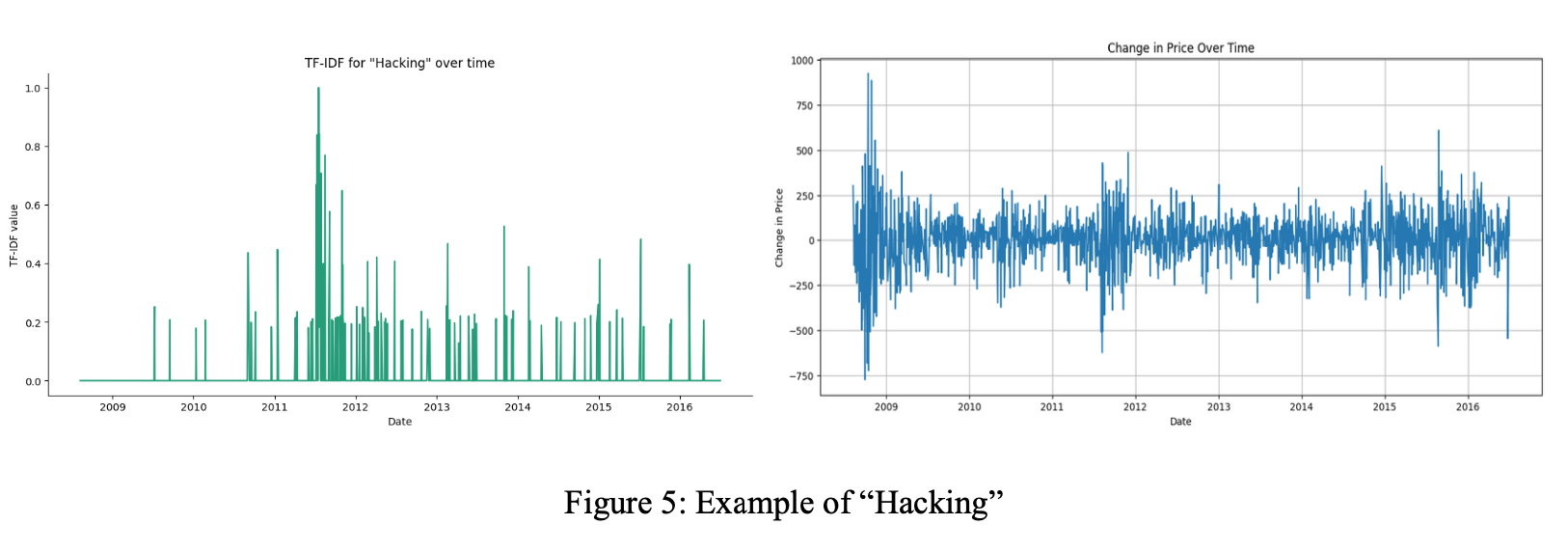
To evaluate model performance, various metrics were considered, including accuracy, precision, recall, F1 score, and ROC-AUC. The classification models—Random Forest, Logistic Regression, and Naive Bayes—were assessed based on their ability to predict stock price movements. In addition to the classification models, the linear regression model provided valuable insights into how sentiment and specific keywords influence the DJIA. By analyzing the regression coefficients, it was observed that certain words related to geopolitical issues, natural disasters, and health crises had a stronger influence on the DJIA. For instance, words like "cancer" and "hacking" were found to have a significant negative impact, indicating that such topics may trigger negative market sentiment.