Equity Price Predictor
Overview
This application focuses on predicting daily equity prices through XGBoost model. The analysis leverages the S&P 500 and NASDAQ 100 indices as initial training data to reflect broader market trends.
Data Preparation
Daily updated historical trading data, including open, high, low, close prices, and trading volume, was collected through Restful API. A 14-day lagged feature was engineered to capture relevant trends, allowing the model to utilize past performance in predicting current prices.
Dynamic Model Development
A flexible XGBoost model was implemented to generate predictions based on user-defined stock symbols, enabling tailored forecasting. The model achieved an impressive R² score of 0.91, indicating a high level of predictive accuracy. However, performance variance was observed across different time periods.
Feature Engineering
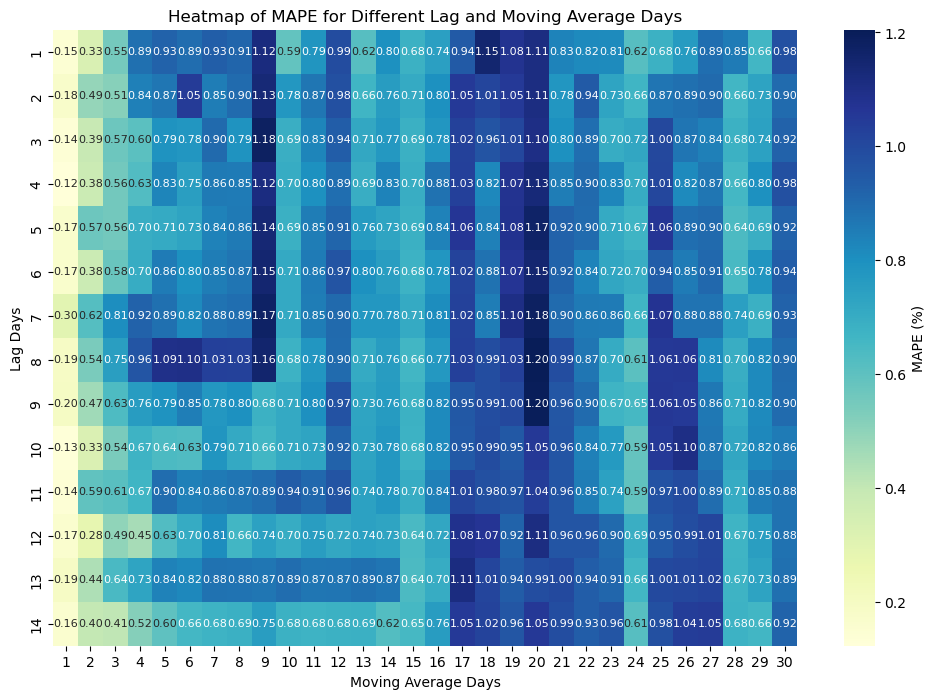
To reduce the impact of time series characteristics and periodic patterns, moving averages were introduced as additional features. A systematic approach was employed to evaluate the optimal combination of lagged features (ranging from 1 to 14 days) and moving averages (from 1 to 30 days). Heatmap analysis identified the optimal configuration of a 15-day and 24-day moving average in conjunction with a 10-day lag as yielding superior performance.
Model Evaluation and Optimization
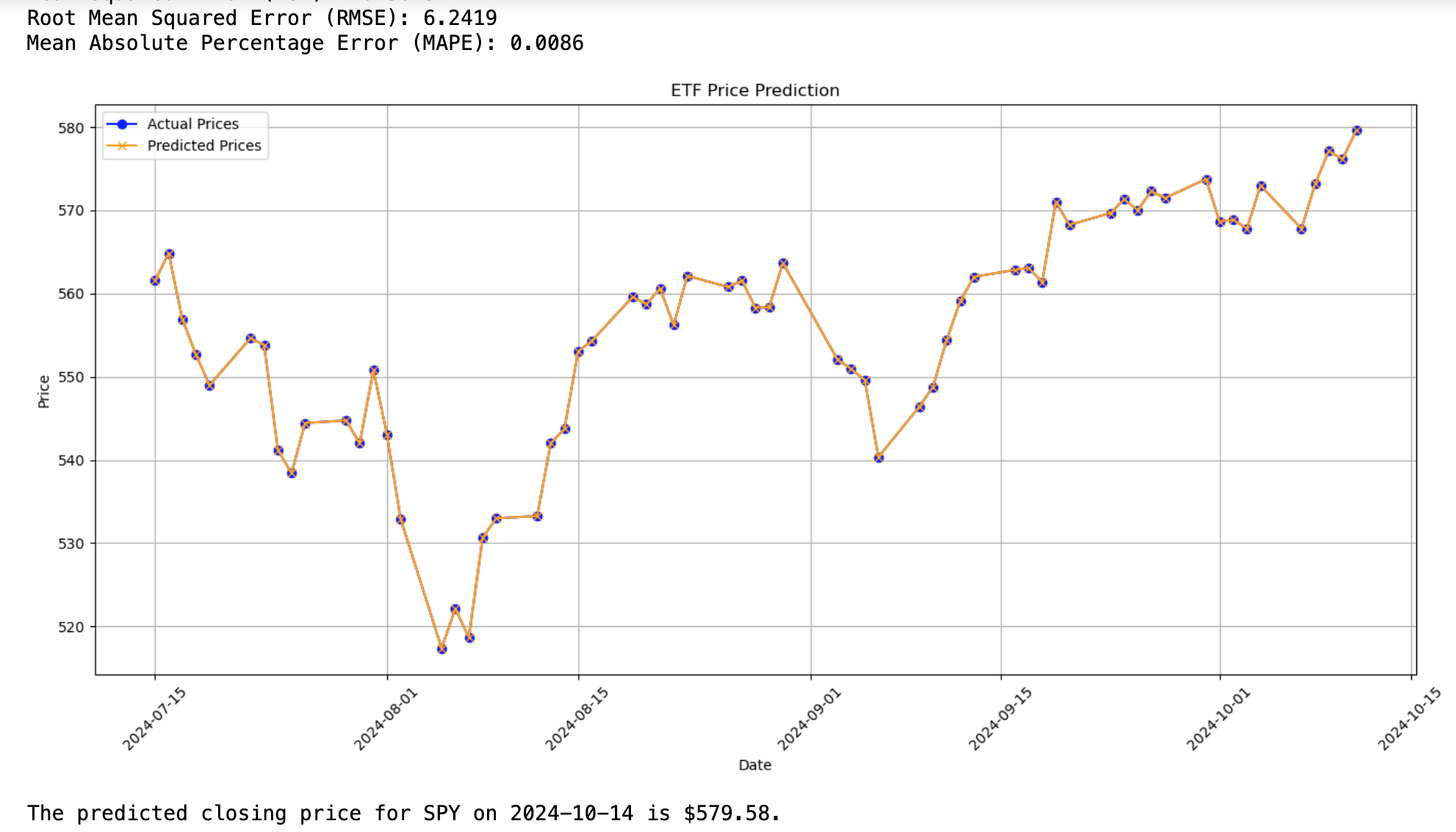
Mean Absolute Percentage Error (MAPE) was utilized as the primary evaluation metric. Following the implementation of moving averages, the MAPE improved significantly to 0.008. To address the identified issue of overfitting, regularization techniques (L1 or L2) were considered, and cross-validation methods were applied to enhance model stability.
Integration of Additional Features
Future iterations will explore the incorporation of additional financial indicators, such as technical indicators (e.g., RSI, MACD) and fundamental metrics (e.g., P/E ratio), to further enhance predictive accuracy and robustness.
Backtesting Framework
A backtesting framework will be developed to assess the model's performance on unseen data over time, validating its effectiveness in real-world trading scenarios.
Interpretability and Insights
An analysis of feature importance will be conducted to identify the most influential variables in the prediction process, enhancing the model's interpretability. Additionally, SHAP (SHapley Additive exPlanations) values will be utilized to provide insights into individual predictions.